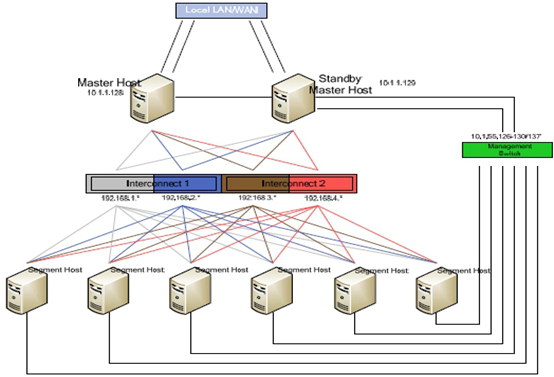
首先,需要评估目标数据库数据所需要的空间容量。建议了解客户搭建Greenplum数据库的具体应用。举例:估计数据库所需空间为U,数据库需要启用Mirror,磁盘阵列总可用空间为D(Raid之后)。空间规划服务和如下公式:
2 * U + U / 3 = D * 70%
磁盘空间D平均分配到各个Segment服务器上。
Master需要相应的空间。使用服务器内置硬盘的计算方式类似。
netstat-n|awk'/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
结果类似如下格式:
ESTABLISHED 23
TIME_WAIT 707
ab命令简单压力测试
ab-n50000000-c10http://127.0.0.1:8080/
uwsgi reload
psafx;kill-HUP$pid_of_uwsgi
xargs相关
find . -type f -name "*.jpg" -print | xargs tar -czvf images.tar.gz
echo"nameXnameXnameXname"| xargs -dX
name name name name
echo"nameXnameXnameXname"| xargs -dX -n2
name name
name name
多行输入单行输出:
cat test.txt | xargs
a b c d e f g h i j k l m n o p q r s t u v w x y z
压缩加速
tar --use-compress-program=pigz -xvpf PKG-20180627.tar.gz